Speech-to-Text streaming demo in React

Transcribing live streamed audio to text has become more and more popular. It’s useful in preparing subtitles or archiving conversation in text mode. ASR – automatic speech recognition – uses advanced machine learning solutions to analyze the context of speech and return text data.
ASR Demo
In this example, we’re going to create a React Component that can be reused in your application. It uses the AWS SDK – Client Transcribe Streaming package to connect to the Amazon Transcribe service using web socket. Animated GIF ASR-streaming-demo.gif presents what we are going to build.
Process an audio file or a live stream
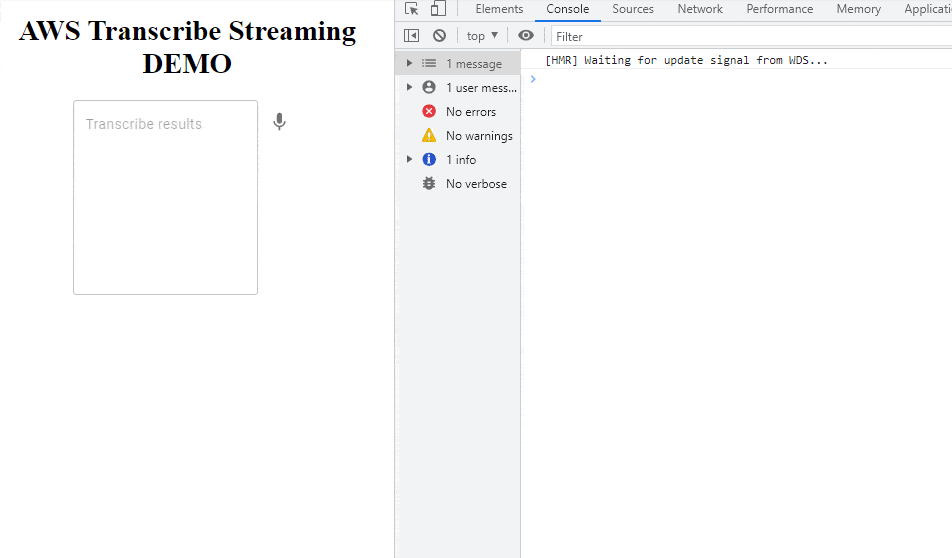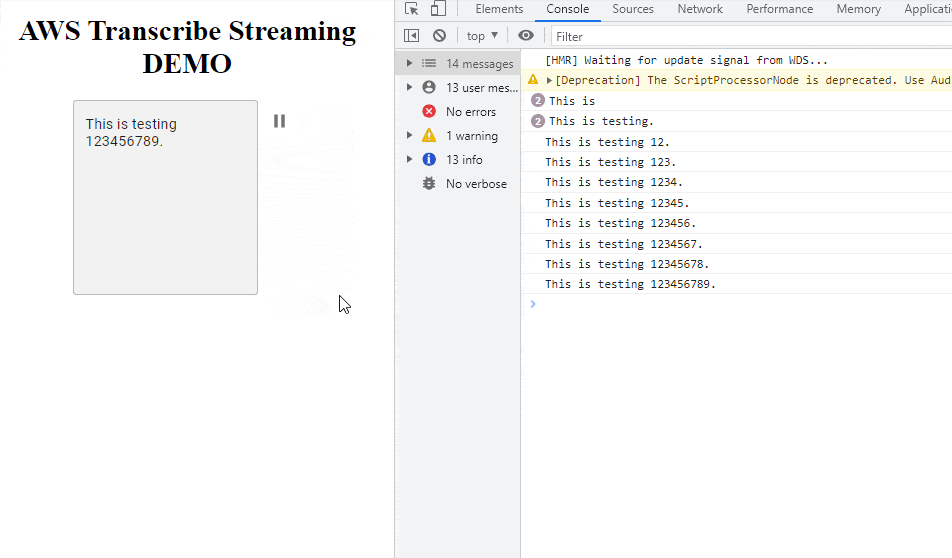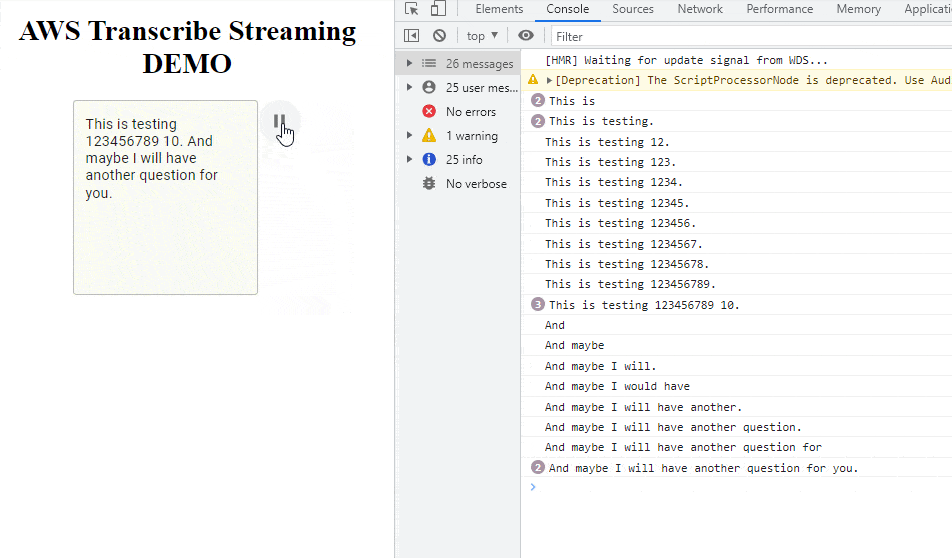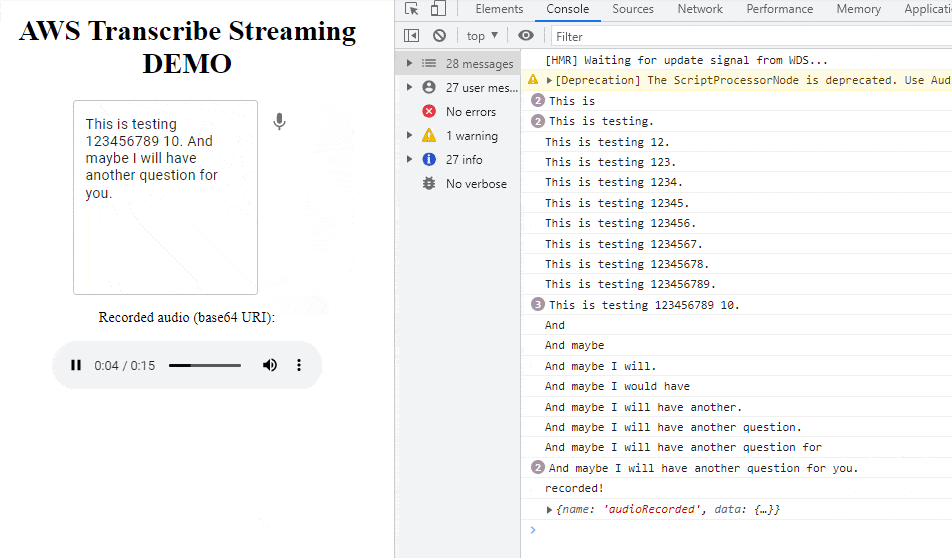
There are two modes we can use: uploading an audio file which will be added as a transcription job and wait for results or live streaming using websocket where the response is instant. This demo will focus on streaming audio where we can see live text recognized returned from API.
ASR in your language
In the config file we can specify the language code for our audio conversation. The most popular language – English – uses lang code: ‘en-US’. AWS Transcribe currently supports over 30 languages, more info at: https://docs.aws.amazon.com/transcribe/latest/dg/supported-languages.html
Audio data format
To achieve good results of Speech to Text recognition, we need to provide a proper audio format that is sent to AWS Transcribe API. It expects audio to be encoded as PCM data. The sample rate is also important, having better quality of voice means we will receive better results. Currently, ‘en-US’ supports sample rates up to 48,000 Hz, and this value was optimal during our tests.
Recording audio as base64
As an additional feature, we’ve implemented saving audio as a base64 audio file. RecordRTC library uses the MediaRecorder Browser API to record voice from microphone. Received BLOB format is converted to base64 which can be easily saved as an archived conversation, or optionally sent to S3 storage.
Audio saved in Chrome is missing duration
The Chrome browser features a bug that was identified in 2016: a file saved using MediaRecorder has malformed metadata, which causes the played file to have incorrect length (duration). As a result, the file recorded in Chrome is not seekable: webm and weba files can be played from the beginning, but searching through them is difficult / impossible.
The issue was reported to https://bugs.chromium.org/p/chromium/issues/detail?id=642012, but has not been fixed yet. There are some existing workarounds, for example: using the ts-ebml Reader and fixing the metadata part of the file. To fix missing duration in Chrome, we’re using the injectMetadata method.
Transcription confidence scores
While doing live speech-to-text recognition, AWS returns a confidence score between 0 and 1. It’s not an accuracy measurement, but rather the service’s self-evaluation on how well it may have transcribed a word. Having this value we can specify the confidence threshold and decide which text data should be saved.
In the presented demo, we will make input text background green only when the receiving data is not partial (AWS has already analyzed the text and is confident with the result). The attached screenshot shows “partial results”. Only when the sentence is finished, the transcription will be matching audio.
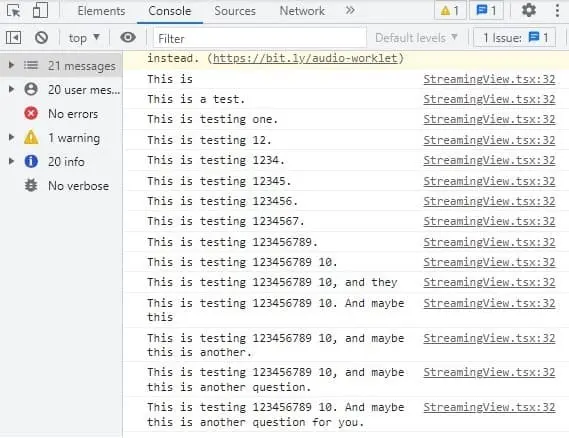
Configure AWS Transcribe
To start using streaming we need to obtain: accessKey, secretAccessKey, and choose the AWS region. The configuration can be set up in: src/SpeechToText/transcribe.constants.ts
The main application is just text area and a microphone icon. After clicking the icon, React will connect with transcribe websocket and will start voice analyzing. After clicking Pause, the audio element will appear with autoplay enabled. The source of audio (src) is: base64 URI content of just recorded voice message.
// src/App.js
import React, { useState, useEffect } from 'react';
import './App.css';
import TextField from '@material-ui/core/TextField';
import StreamingView from './SpeechToText/StreamingView';
import {
BrowserRouter as Router,
Switch,
Route,
} from 'react-router-dom';
function App() {
// eslint-disable-next-line
const [inputMessageText, setInputMessageText] = useState("");
// eslint-disable-next-line
const [recordedAudio, setRecordedAudio] = useState(null);
useEffect(() => {
if(recordedAudio){
console.log("recorded!");
console.log(recordedAudio);
}
}, [recordedAudio]);
return (
<div className="App">
<Router>
<Switch>
<Route path="/">
<h1>AWS Transcribe Streaming DEMO</h1>
<TextField
variant="outlined"
placeholder="Transcribe results"
minRows={10}
value={inputMessageText}
readOnly={true}
multiline
maxRows={Infinity}
id="input1"
/>
<StreamingView setInputMessageText={setInputMessageText} setRecordedAudio={setRecordedAudio} />
{ recordedAudio && <p>Recorded audio (base64 URI):</p> }
{ recordedAudio && <audio src={recordedAudio.data.audioRecorded} autoPlay controls /> }
</Route>
</Switch>
</Router>
</div>
);
}
export default App;
And some additional CSS styles:
/* src/App.js */
.App {
text-align: center;
}
.is-final-recognized .MuiTextField-root{
animation: ctcompleted 1s 1;
}
.is-recognizing .MuiTextField-root{
background:rgba(0,0,0,.05);
}
@keyframes ctcompleted
{
0% {background:#dcedc8;}
25% {background:#dcedc8;}
75% {background:#dcedc8;}
100% {background:inherit;}
}
Transcribe API keys
The previously generated AWS API keys should be hardcoded in the config object.
// src/SpeechToText/transcribe.constants.ts
const transcribe = {
accessKey: 'AAA',
secretAccessKey: 'BBB',
// default config
language: 'en-US',
region: 'eu-west-1',
sampleRate: 48000,
vocabularyName: '',
};
export default transcribe;StreamingView React component
The reusable component for audio streaming receives text from API and passes the recorded audio to the parent. It’s written using TypeScript, the icons are imported from material-ui.
// src/SpeechToText/StreamingView.tsx
import React, { useEffect, useMemo, useState } from 'react';
import IconButton from '@material-ui/core/IconButton';
import KeyboardVoiceIcon from '@material-ui/icons/KeyboardVoice';
import PauseIcon from '@material-ui/icons/Pause';
import TranscribeController from './transcribe.controller';
import { setBodyClassName } from './helpers';
import transcribe from "./transcribe.constants";
const StreamingView: React.FC<{
componentName: 'StreamingView';
setInputMessageText: (arg1: string) => void;
setRecordedAudio: (arg1: any) => void;
}> = ({setInputMessageText, setRecordedAudio}) => {
const [transcribeConfig] = useState(transcribe);
const [recognizedTextArray, setRecognizedTextArray] = useState<string[]>([]);
const [recognizingText, setRecognizingText] = useState<string>('');
const [started, setStarted] = useState(false);
const transcribeController = useMemo(() => new TranscribeController(), []);
useEffect(() => {
transcribeController.setConfig(transcribeConfig);
setStarted(false);
}, [transcribeConfig, transcribeController]);
useEffect(() => {
const display = ({ text, final }: { text: string; final: boolean }) => {
// debug
console.log(text);
if (final) {
setRecognizingText('');
setRecognizedTextArray((prevTextArray) => [...prevTextArray, text]);
setBodyClassName("is-recognizing","is-final-recognized");
} else {
setBodyClassName("is-final-recognized","is-recognizing");
setRecognizingText(text);
}
};
// @ts-ignore
const getAudio = ({aaa}: { aaa: Blob}) => {
let customObj = {};
if(aaa.type){
// @ts-ignore
customObj.audioType = aaa.type;
}
// convert Blob to base64 uri
let reader = new FileReader();
reader.readAsDataURL(aaa);
reader.onloadend = () => {
if(reader.result){
// @ts-ignore
customObj.audioRecorded = reader.result.toString();
setRecordedAudio({name: "audioRecorded", data: customObj});
}
}
}
transcribeController.on('recognized', display);
transcribeController.on('newAudioRecorded', getAudio);
return () => {
transcribeController.removeListener('recognized', display);
transcribeController.removeListener('newAudioRecorded', getAudio);
};
}, [transcribeController, setRecordedAudio]);
useEffect(() => {
(async () => {
if (started) {
setRecognizedTextArray([]);
setRecognizingText('');
setRecordedAudio(null);
await transcribeController.init().catch((error: Error) => {
console.log(error);
setStarted(false);
});
} else {
await transcribeController.stop();
}
})();
}, [started, transcribeController, setRecordedAudio]);
useEffect(() => {
const currentRecognizedText = [...recognizedTextArray, recognizingText].join(' ');
setInputMessageText(currentRecognizedText);
}, [recognizedTextArray, recognizingText, setInputMessageText]);
return (<>
<IconButton onClick={() => {
setStarted(!started);
}}>
{! started ? <KeyboardVoiceIcon/> : <PauseIcon />}
</IconButton>
</>
);
};
export default StreamingView;
Transcribe Streaming Client
The main part of the application is the controller, where communication between AWS Transcribe and Client is established. The stream sends PCM encoded audio and receives partial results through websocket. RecordRTC records audio in the background using native MediaRecorder API, which is supported by all modern browsers.
// src/SpeechToText/transcribe.controller.ts
import {
TranscribeStreamingClient,
StartStreamTranscriptionCommand,
StartStreamTranscriptionCommandOutput,
} from '@aws-sdk/client-transcribe-streaming';
import MicrophoneStream from 'microphone-stream';
import { PassThrough } from 'stream';
import { EventEmitter } from 'events';
import transcribeConstants from './transcribe.constants';
import { streamAsyncIterator, EncodePcmStream } from './helpers';
import { Decoder, tools, Reader } from 'ts-ebml';
import RecordRTC from 'recordrtc';
class TranscribeController extends EventEmitter {
private audioStream: MicrophoneStream | null;
private rawMediaStream: MediaStream | null | any;
private audioPayloadStream: PassThrough | null;
private transcribeConfig?: typeof transcribeConstants;
private client?: TranscribeStreamingClient;
private started: boolean;
private mediaRecorder: RecordRTC | null;
private audioBlob: Blob | null;
constructor() {
super();
this.audioStream = null;
this.rawMediaStream = null;
this.audioPayloadStream = null;
this.started = false;
this.mediaRecorder = null;
this.audioBlob = null;
}
setAudioBlob(Blob: Blob | null){
this.audioBlob = Blob;
const aaa = this.audioBlob;
this.emit('newAudioRecorded', {aaa});
}
hasConfig() {
return !!this.transcribeConfig;
}
setConfig(transcribeConfig: typeof transcribeConstants) {
this.transcribeConfig = transcribeConfig;
}
validateConfig() {
if (
!this.transcribeConfig?.accessKey ||
!this.transcribeConfig.secretAccessKey
) {
throw new Error(
'missing required config: access key and secret access key are required',
);
}
}
recordAudioData = async (stream: MediaStream) =>{
this.mediaRecorder = new RecordRTC(stream,
{
type: "audio",
disableLogs: true,
});
this.mediaRecorder.startRecording();
// @ts-ignore
this.mediaRecorder.stream = stream;
return stream;
}
stopRecordingCallback = () => {
// @ts-ignore
this.injectMetadata(this.mediaRecorder.getBlob())
// @ts-ignore
.then(seekableBlob => {
this.setAudioBlob(seekableBlob);
// @ts-ignore
this.mediaRecorder.stream.stop();
// @ts-ignore
this.mediaRecorder.destroy();
this.mediaRecorder = null;
})
}
readAsArrayBuffer = (blob: Blob) => {
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.readAsArrayBuffer(blob);
reader.onloadend = () => { resolve(reader.result); };
reader.onerror = (ev) => {
// @ts-ignore
reject(ev.error);
};
});
}
injectMetadata = async (blob: Blob) => {
const decoder = new Decoder();
const reader = new Reader();
reader.logging = false;
reader.drop_default_duration = false;
return this.readAsArrayBuffer(blob)
.then(buffer => {
// fix for Firefox
if(! blob.type.includes('webm')){
return blob;
}
// @ts-ignore
const elms = decoder.decode(buffer);
elms.forEach((elm) => { reader.read(elm); });
reader.stop();
const refinedMetadataBuf =
tools.makeMetadataSeekable(reader.metadatas, reader.duration, reader.cues);
// @ts-ignore
const body = buffer.slice(reader.metadataSize);
return new Blob([ refinedMetadataBuf, body ], { type: blob.type });
});
}
async init() {
this.started = true;
if (!this.transcribeConfig) {
throw new Error('transcribe config is not set');
}
this.validateConfig();
this.audioStream = new MicrophoneStream();
this.rawMediaStream = await window.navigator.mediaDevices.getUserMedia({
video: false,
audio: {
sampleRate: this.transcribeConfig.sampleRate,
},
}).then(this.recordAudioData, this.microphoneAccessError)
.catch(function(err) {
console.log(err);
});
await this.audioStream.setStream(this.rawMediaStream);
this.audioPayloadStream = this.audioStream
.pipe(new EncodePcmStream())
.pipe(new PassThrough({ highWaterMark: 1 * 1024 }));
// creating and setting up transcribe client
const config = {
region: this.transcribeConfig.region,
credentials: {
accessKeyId: this.transcribeConfig.accessKey,
secretAccessKey: this.transcribeConfig.secretAccessKey,
},
};
this.client = new TranscribeStreamingClient(config);
const command = new StartStreamTranscriptionCommand({
LanguageCode: this.transcribeConfig.language,
MediaEncoding: 'pcm',
MediaSampleRateHertz: this.transcribeConfig.sampleRate,
AudioStream: this.audioGenerator.bind(this)(),
});
try {
const response = await this.client.send(command);
this.onStart(response);
} catch (error) {
if (error instanceof Error) {
}
} finally {
// finally.
}
}
microphoneAccessError = (error:any) => {
console.log(error);
}
async onStart(response: StartStreamTranscriptionCommandOutput) {
try {
if (response.TranscriptResultStream) {
for await (const event of response.TranscriptResultStream) {
const results = event.TranscriptEvent?.Transcript?.Results;
if (results && results.length > 0) {
const [result] = results;
const final = !result.IsPartial;
const alternatives = result.Alternatives;
if (alternatives && alternatives.length > 0) {
const [alternative] = alternatives;
const text = alternative.Transcript;
this.emit('recognized', { text, final });
}
}
}
}
} catch (error) {
console.log(error);
}
}
async stop() {
this.started = false;
// request to stop recognition
this.audioStream?.stop();
this.audioStream = null;
this.rawMediaStream = null;
this.audioPayloadStream?.removeAllListeners();
this.audioPayloadStream?.destroy();
this.audioPayloadStream = null;
this.client?.destroy();
this.client = undefined;
// @ts-ignore
if(this.mediaRecorder){
this.mediaRecorder.stopRecording(this.stopRecordingCallback);
}
}
async *audioGenerator() {
if (!this.audioPayloadStream) {
throw new Error('payload stream not created');
}
for await (const chunk of streamAsyncIterator(this.audioPayloadStream)) {
if (this.started) {
yield { AudioEvent: { AudioChunk: chunk } };
} else {
break;
}
}
}
}
export default TranscribeController;
Helpers for audio encoding
Additional methods for manipulating audio are defined in helpers.ts. It also includes a function for changing DOM body className.
// src/SpeechToText/helpers.ts
/* eslint-disable no-await-in-loop */
/* eslint-disable @typescript-eslint/no-explicit-any */
import { PassThrough } from 'stream';
import { Transform, TransformCallback } from 'stream';
import MicrophoneStream from 'microphone-stream';
export function mapRoute(text: string) {
return `${text}-section`;
}
export async function* fromReadable(stream: PassThrough) {
let exhausted = false;
const onData = () =>
new Promise((resolve) => {
stream.once('data', (chunk: any) => {
resolve(chunk);
});
});
try {
while (true) {
const chunk = (await onData()) as any;
if (chunk === null) {
exhausted = true;
break;
}
yield chunk;
}
} finally {
if (!exhausted) {
stream.destroy();
}
}
}
export function streamAsyncIterator(stream: PassThrough) {
// Get a lock on the stream:
// const reader = stream.getReader();
return {
[Symbol.asyncIterator]() {
return fromReadable(stream);
},
};
}
/**
* encodePcm
*/
export function encodePcm(chunk: any) {
const input = MicrophoneStream.toRaw(chunk);
let offset = 0;
const buffer = new ArrayBuffer(input.length * 2);
const view = new DataView(buffer);
for (let i = 0; i < input.length; i++, offset += 2) {
const s = Math.max(-1, Math.min(1, input[i]));
view.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7fff, true);
}
return Buffer.from(buffer);
}
export class EncodePcmStream extends Transform {
_transform(chunk: any, encoding: string, callback: TransformCallback) {
const buffer = encodePcm(chunk);
this.push(buffer);
callback();
}
}
export const setBodyClassName = (removeClass:string, addClass:string) => {
let body = document.getElementsByTagName('body')[0];
if(removeClass){
body.classList.remove(removeClass);
}
if(addClass){
body.classList.add(addClass);
}
}
Used NPM libraries
The app uses different dependencies. The most important ones are:
“@aws-sdk/client-transcribe-streaming”: “^3.3.0”,
“microphone-stream”: “^6.0.1”,
“react”: “^17.0.2”,
“recordrtc”: “^5.6.2”,
“ts-ebml”: “^2.0.2”,
“typescript”: “^4.5.2”,
Below is a full list of the used npm libraries ( package.json ):
"dependencies": {
"@aws-sdk/client-transcribe-streaming": "^3.3.0",
"@babel/core": "7.9.0",
"@material-ui/core": "^4.9.8",
"@material-ui/icons": "^4.9.1",
"@types/node": "^12.20.37",
"@types/react": "^17.0.37",
"@types/recordrtc": "^5.6.8",
"@typescript-eslint/eslint-plugin": "^2.10.0",
"@typescript-eslint/parser": "^2.10.0",
"babel-eslint": "10.1.0",
"babel-jest": "^24.9.0",
"babel-loader": "8.1.0",
"babel-plugin-named-asset-import": "^0.3.6",
"babel-preset-react-app": "^9.1.2",
"camelcase": "^5.3.1",
"case-sensitive-paths-webpack-plugin": "2.3.0",
"css-loader": "3.4.2",
"dotenv": "8.2.0",
"dotenv-expand": "5.1.0",
"eslint": "^6.6.0",
"eslint-config-react-app": "^5.2.1",
"eslint-loader": "3.0.3",
"eslint-plugin-flowtype": "4.6.0",
"eslint-plugin-import": "2.20.1",
"eslint-plugin-jsx-a11y": "6.2.3",
"eslint-plugin-react": "7.19.0",
"eslint-plugin-react-hooks": "^1.6.1",
"file-loader": "4.3.0",
"fs-extra": "^8.1.0",
"html-webpack-plugin": "4.0.0-beta.11",
"jest": "24.9.0",
"jest-environment-jsdom-fourteen": "1.0.1",
"jest-watch-typeahead": "0.4.2",
"microphone-stream": "^6.0.1",
"mini-css-extract-plugin": "0.9.0",
"optimize-css-assets-webpack-plugin": "5.0.3",
"pnp-webpack-plugin": "1.6.4",
"postcss-flexbugs-fixes": "4.1.0",
"postcss-loader": "3.0.0",
"postcss-normalize": "8.0.1",
"postcss-preset-env": "6.7.0",
"postcss-safe-parser": "4.0.1",
"react": "^17.0.2",
"react-app-polyfill": "^1.0.6",
"react-dev-utils": "^10.2.1",
"react-dom": "^17.0.2",
"react-router-dom": "^5.1.2",
"recordrtc": "^5.6.2",
"resolve": "1.15.0",
"resolve-url-loader": "3.1.1",
"sass-loader": "8.0.2",
"style-loader": "0.23.1",
"terser-webpack-plugin": "2.3.5",
"ts-ebml": "^2.0.2",
"ts-pnp": "1.1.6",
"typescript": "^4.5.2",
"url-loader": "2.3.0",
"web-vitals": "^1.1.2",
"webpack": "4.42.0",
"webpack-dev-server": "3.10.3",
"webpack-manifest-plugin": "2.2.0",
"workbox-webpack-plugin": "4.3.1"
},
Typescript
The application is written using Typescript. For proper compilation we need to have tsconfig.json placed in the main directory.
// tsconfig.json
{
"compilerOptions": {
"target": "es5",
"lib": ["dom", "dom.iterable", "esnext"],
"allowJs": true,
"skipLibCheck": true,
"esModuleInterop": true,
"allowSyntheticDefaultImports": true,
"strict": true,
"forceConsistentCasingInFileNames": true,
"noFallthroughCasesInSwitch": true,
"module": "esnext",
"moduleResolution": "node",
"resolveJsonModule": true,
"isolatedModules": true,
"noEmit": true,
"jsx": "react-jsx",
"typeRoots": ["./node_modules/@types", "./@types"]
},
"include": ["src/**/*"],
"exclude": ["./node_modules", "./node_modules/*"]
}
AWS Transcribe Streaming DEMO
We use NODE v16.13.0 and React 17.0.2. To run the application, 2 commands should be performed:
npm install
npm run start
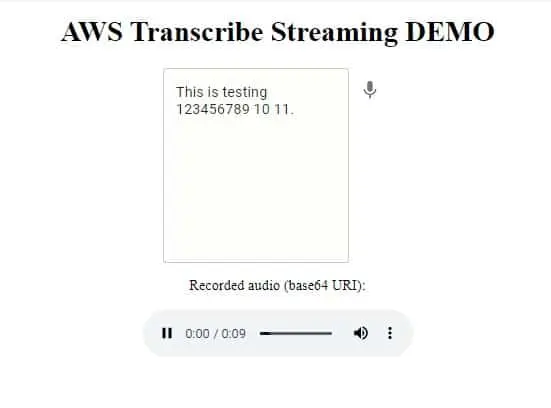
Here is a screenshot of an example visible in the browser. You will be able to test Speech-to-text functionality and implement it in your application.
Thanks to Muhammad Qasim whose demo inspired this article. More info at: https://github.com/qasim9872/react-amazon-transcribe-streaming-demo
Troubleshooting
Problem:
Failed to compile.
src/SpeechToText/transcribe.controller.ts
TypeScript error in src/SpeechToText/transcribe.controller.ts(173,14):
Property 'pipe' does not exist on type 'MicrophoneStream'. TS2339
Solution:
add proper Typescript types definition to the main directory ( @types/microphone-stream/index.d.ts ):
// @types/microphone-stream/index.d.ts
declare module 'microphone-stream' {
import { Readable } from 'stream';
export declare class MicrophoneStream extends Readable {
static toRaw(chunk: any): Float32Array;
constructor(opts?: {
stream?: MediaStream;
objectMode?: boolean;
bufferSize?: null | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16384;
context?: AudioContext;
});
public context: AudioContext;
setStream(mediaStream: MediaStream): Promise<void>;
stop(): void;
pauseRecording(): void;
playRecording(): void;
}
export default MicrophoneStream;
}
That’s it for today’s tutorial. Make sure to follow us for other useful tips and guidelines.
Do you need someone to implement this solution for you? Check out our specialists for hire in the outsourcing section. Are you considering a global project and are uncertain how to proceed? Or you need a custom web development services? Reach us now!
















![How to Fight AI Hallucinations About Your Brand [ready-to-use prompt inside]](https://www.createit.com/wp-content/uploads/2026/02/How-to-Fight-AI-Hallucinations-355x200.jpg)


